近日,我校几何计算与智能媒体技术研究团队在多源图像融合领域取得两项科研成果,有助于解决无人系统在复杂场景中感知困难的问题。两项研究面向国家重大需求,基于多源图像的成像特性和真实环境的干扰因素,设计出了高效、鲁棒、精准感知的红外可见光图像融合算法。
随着传感硬件的快速发展,多模态成像在监控、自动驾驶等实际应用中受到了广泛关注,其中红外与可见光成像不仅有利于提升良好成像环境下的视觉感知,而且极大地促进了恶劣成像环境下的视觉感知任务的完成。多模态成像应用最为广泛的是多源图像融合领域,然而目前的图像融合方法存在目标不清晰、感知性能差以及难以适应多源图像未对齐现象等缺陷,如何克服这些问题是当前多源图像融合领域面临的重大挑战。
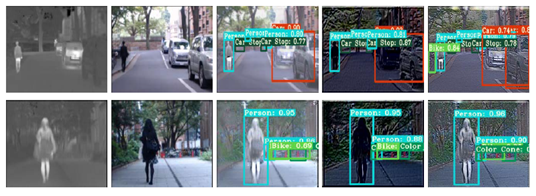
研究成果“Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection”由软件学院博士研究生刘晋源,国际信息与软件学院樊鑫教授、本科生黄展搏、本科生吴冠尧、刘日升教授、仲维副教授,罗钟铉教授共同合作完成。该项研究针对多模态图像融合存在的融合后目标不清晰、视觉质量和感知性能差等问题,提出了联合图像融合与下游视觉任务的双层优化框架。该框架“求同存异”探究了融合图像与源图像中背景与显著目标物两方面的差异,从而更好地从红外和可见光源图像中提取并保留目标的结构信息和纹理细节。此外,研究还构建了一个红外和可见光传四目同步成像系统,建立了大型全天候多场景数据集(4000+成对数据及20000+的标注)。该研究方法不但在视觉上具有吸引力、定性分析中各融合指标有明显优势,而且在多种挑战环境的场景下,融合后的目标检测结果的mAP率较现有最先进的方法提升10%以上。

研究成果“Unsupervised Misaligned Infrared and Visible Image Fusion via Cross-Modality Image Generation and Registration”由软件学院博士研究生王迪、刘晋源,国际信息与软件学院樊鑫教授、刘日升教授共同完成。该项研究针对现有多模态图像融合方法难以处理未对齐图像的空间形变、导致融合图像产生边缘重影等问题,提出了一种面向红外与可见光图像融合的无监督跨模态“配准-融合”联合框架。该框架致力于缩小多源图像模态间的固有差异,提出专门处理多模态图像对齐的“生成-配准”方法,实现了红外与可见光图像的有效对齐。该方法极大地促进了未对齐图像的融合性能,有效抑制了融合图像的结构扭曲与边缘重影,从而为下游视觉任务提供高质量的融合图像。
相关成果分别被计算机视觉重要学术会议CVPR 2022和人工智能领域重要学术会议IJCAI 2022接收,均被邀请在大会上作口头报告。
我校几何计算与智能媒体技术研究团队与立命馆大学合作建立健康医疗智能计算联合研究中心,研究课题包括机器学习、深度学习、计算机视觉、多媒体技术、优化方法等当前最前沿的领域,及其在医疗和健康领域中的应用。近年来在IEEE TPAMI、TIP、NeurIPS、CVPR、ECCV、IJCAI、AAAI、ACM MM等人工智能、多媒体技术等多领域的重要期刊及会议上发表论文达100余篇。该团队也一直致力于面向国家重大需求,加强关键共性技术研究,已经在全天候车载多波段立体视觉感知单元,以及水下目标自主抓取机器人等应用研发方面取得突破。
来源:校党委宣传部
责任编辑:潘树孟
